개요
희소 벡터(Sparse Vector)와 밀집 벡터(Dense Vector)는 데이터를 수치적으로 표현하는 두 가지 근본적으로 다른 접근 방식이다. 희소 벡터는 명시적 특징 표현에, 밀집 벡터는 의미적 표현에 강점을 가진다.
머신러닝과 자연어 처리에서 이 두 방식은 각각의 장단점으로 인해 서로 다른 용도로 활용되며, 최근에는 두 접근법을 결합한 하이브리드 방식이 주목받고 있다.
비교표
| 측면 | 희소 벡터 | 밀집 벡터 |
|---|---|---|
| 차원 수 | 수천~수만 차원 | 100~1000 차원 |
| 0의 비율 | 95% 이상 | 거의 없음 |
| 생성 방법 | TF-IDF, Bag-of-Words, One-Hot, SPLADE | Word2Vec, GloVe, BERT, GPT, Sentence-BERT |
| 해석 가능성 | 높음 (각 차원이 명시적 특징) | 낮음 (학습된 추상 표현) |
| 의미 이해 | 약함 (구문적 매칭) | 강함 (의미적 유사성) |
| 학습 필요성 | 불필요 (전통적 기법), 필요 (SPLADE) | 필수 (신경망 학습) |
| 저장 공간 | 효율적 (희소 저장 시) | 고정 크기 |
| 계산 비용 | 낮음 (생성), 높음 (고차원 연산) | 높음 (학습), 낮음 (저차원 연산) |
| 검색/인덱싱 | 역색인 (Inverted Index) | HNSW, FAISS, ScaNN |
| 주요 활용 | BM25 랭킹, 키워드 검색 | 시맨틱 검색, 추천 시스템 |
| 사용 시기 | 정확한 매칭 중요 | 의미적 유사성 중요 |
시각화로 보는 차이
희소 벡터와 밀집 벡터의 본질적인 차이는 고차원 공간에서의 분포 패턴에서 명확히 드러난다. 아래 그림은 10,000차원 벡터를 TruncatedSVD로 2차원으로 축소한 결과를 보여준다.
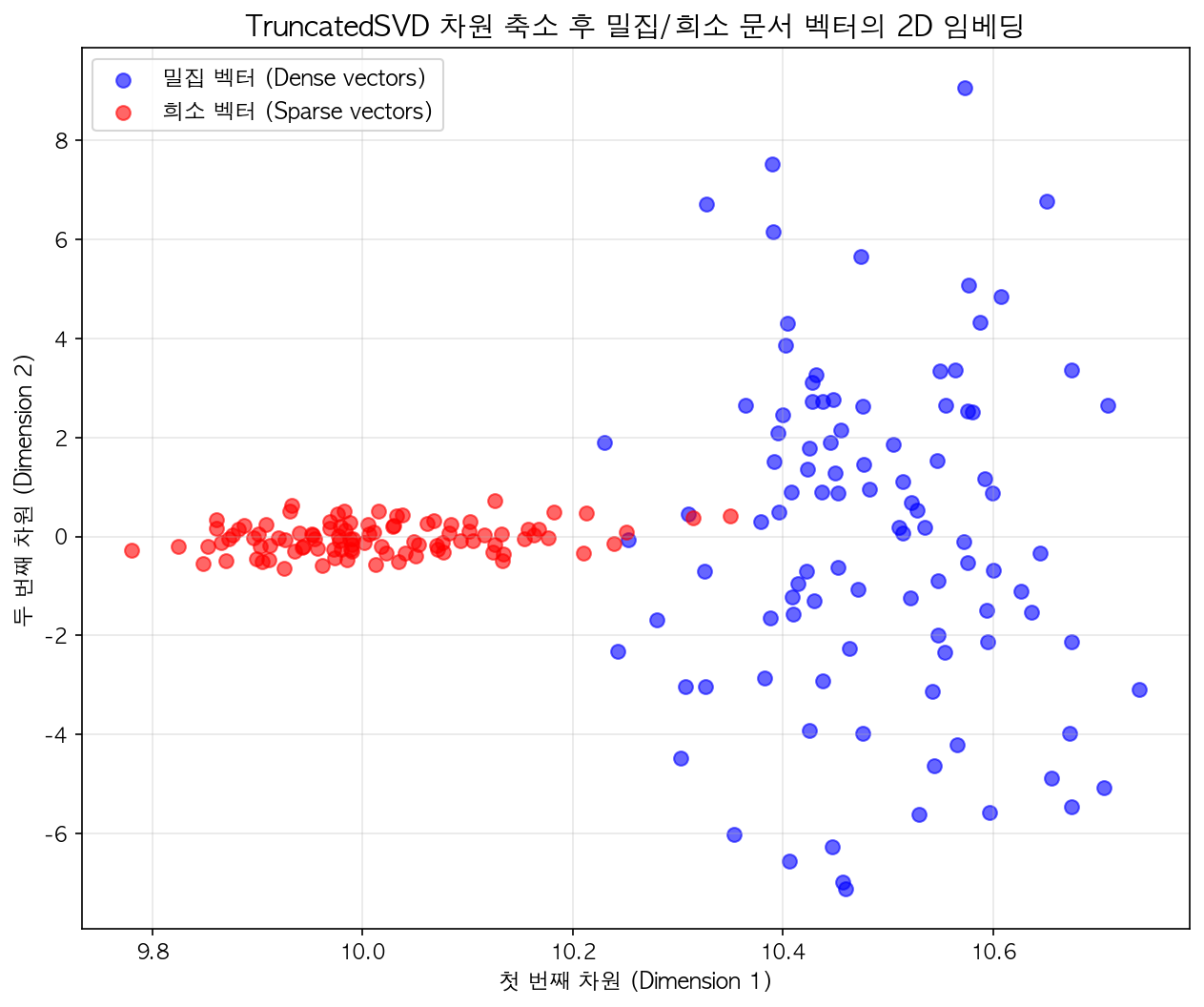
실험 설정
- 어휘 크기: 10,000 단어
- 문서 수: 100개
- 문서당 단어 수: 1,000개
- 차원 축소: TruncatedSVD (10,000D → 2D)
관찰 결과
밀집 벡터 (파란색)
- Bag-of-Words 방식으로 생성
- 각 문서는 1,000개 단어를 포함하므로 약 10% 차원에 값 존재
- 2차원으로 축소 후에도 비교적 밀집된 클러스터 형성
- 유사한 단어 빈도 패턴을 가진 문서들이 가까이 위치
희소 벡터 (빨간색)
- 1% 희소성 (density=0.01)으로 생성
- 대부분의 차원이 0
- 2차원 공간에서 더 넓게 분산된 패턴
- 각 문서가 매우 적은 특징만 활성화하여 분포가 흩어짐
핵심 통찰
차원 축소 후에도 두 벡터 타입의 본질적 특성이 유지된다:
- 밀집 벡터: 정보가 여러 차원에 분산되어 인코딩되어 있어, 축소 후에도 의미 있는 구조를 보존
- 희소 벡터: 소수의 명시적 특징만 활성화되어, 축소 시 정보 손실이 크고 분포가 불규칙
이러한 분포 차이는 각 방식의 장단점과 직접적으로 연결된다. 밀집 벡터는 낮은 차원에서도 효율적인 검색이 가능하며(HNSW 등), 희소 벡터는 역색인을 통한 정확한 키워드 매칭에 유리하다.
언제 무엇을 사용할까?
희소 벡터가 적합한 경우
- 키워드의 정확한 일치가 중요한 검색
- 명시적 특징이 중요한 도메인 (법률, 의료 용어 검색)
- 해석 가능성이 필수적인 경우
- 학습 데이터나 컴퓨팅 자원이 제한적인 경우
- 빠른 프로토타이핑이 필요한 경우
밀집 벡터가 적합한 경우
- 의미적 유사성이 중요한 검색
- 동의어나 유사 표현을 이해해야 하는 경우
- 문맥을 고려한 언어 이해가 필요한 경우
- 충분한 학습 데이터와 자원이 있는 경우
- 다국어나 크로스모달 작업
하이브리드 접근
최근에는 희소 벡터와 밀집 벡터의 장점을 결합하는 하이브리드 검색이 주목받고 있다.
방법
병렬 검색 및 결합
희소 벡터와 밀집 벡터로 각각 검색한 후 결과를 결합한다.
점수 기반 결합:
최종 점수 = α × 희소_점수 + (1-α) × 밀집_점수
여기서 α는 가중치 파라미터로, 작업의 특성에 따라 조정한다.
순위 기반 결합 (RRF): Reciprocal Rank Fusion을 사용하여 순위만으로 결과를 결합할 수 있다. 점수 정규화 문제를 회피하며 더 강건한 결과를 제공한다.
재순위화 (Re-ranking)
1차: 희소 벡터로 빠르게 후보 필터링 (상위 1000개) 2차: 밀집 벡터로 정밀한 순위 결정 (상위 10개)
계산 비용을 줄이면서 높은 정확도를 유지할 수 있다.
장점
- 상호 보완: 키워드의 정확한 매칭과 의미적 유사성을 동시에 활용
- 강건성: 한쪽 방식의 약점을 다른 방식이 보완
- 유연성: 작업 특성에 따라 가중치 조정 가능
- 다양한 의도 대응: 정확한 검색과 탐색적 검색 모두 지원
구현 예시
현대 검색 시스템들이 하이브리드 접근을 지원한다:
- Elasticsearch: BM25 + 벡터 검색 결합
- Weaviate: 키워드 검색 + HNSW 벡터 검색
- Pinecone: 희소-밀집 하이브리드 인덱스
- Vespa: 다중 랭킹 신호 결합
하이브리드 활용 사례
통합 검색 시스템
전자상거래, 기업 문서 검색, 뉴스 플랫폼에서 키워드 검색과 의미 검색을 동시에 제공한다.
예시:
- 사용자가 “편안한 운동화”를 검색하면
- 희소: “운동화” 키워드 정확 매칭
- 밀집: “스니커즈”, “러닝화” 등 유사 제품 포함
- 결과: 정확한 제품 + 관련 제품 모두 제공
전자상거래
정확한 제품명 매칭과 유사 제품 추천을 결합한다.
전략:
- 상품명, 브랜드: 희소 벡터로 정확 매칭
- 설명, 리뷰: 밀집 벡터로 의미적 유사성
- 가중치: 검색 의도에 따라 동적 조정
엔터프라이즈 검색
문서 관리 시스템에서 다양한 검색 요구를 충족한다.
시나리오:
- 법률 문서: 정확한 조항 번호는 희소 벡터, 유사 판례는 밀집 벡터
- 기술 문서: 특정 오류 코드는 희소 벡터, 관련 해결책은 밀집 벡터
- 이메일 검색: 발신자, 날짜는 희소 벡터, 내용은 밀집 벡터
질문-응답 시스템
사용자 질의에 대해 정확한 답변과 관련 정보를 모두 제공한다.
구성:
- 1차: 희소 벡터로 관련 문서 빠르게 필터링
- 2차: 밀집 벡터로 의미적으로 가장 관련 있는 구절 추출
- 3차: 언어 모델로 최종 답변 생성
선택 가이드
프로젝트 초기 단계
희소 벡터로 베이스라인 구축 → 성능 평가 → 필요시 밀집 벡터 도입 → 하이브리드 최적화
리소스 고려
- 제한적: 희소 벡터 (빠른 구현, 낮은 비용)
- 충분함: 밀집 벡터 (높은 품질)
- 최적화: 하이브리드 (최고 성능)
도메인 특성
- 전문 용어 중심: 희소 벡터 중심, 밀집 벡터 보조
- 자연어 중심: 밀집 벡터 중심, 희소 벡터 보조
- 혼합 환경: 하이브리드 균형 접근
참고 자료
기술 문서 및 튜토리얼
- Pinecone: Dense Vector Embeddings for NLP
- Milvus: What are Dense and Sparse Embeddings?
- Weaviate: Hybrid Search Explained
- Elasticsearch: Sparse Vector Embedding
논문
코드 및 실습
- 벡터 검색 - Chapter 2: 희소 벡터와 밀집 벡터 시각화 - 본 문서의 시각화 예제 원본